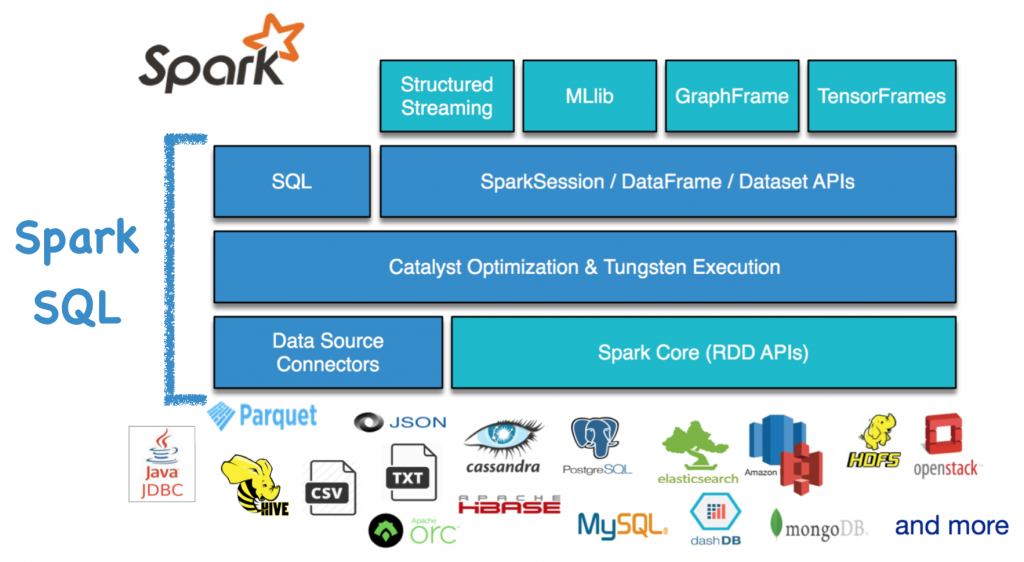
The name of Spark SQL is confusing. Many articles view it as a pure SQL query engine and compare it with the other SQL engines. However, this is inaccurate. SQL is just one of the interfaces of Spark SQL. Spark SQL also has SparkSession, and DataFrame/Dataset APIs. Like the other Spark modules, Spark SQL provides four language supports: Scala, Python, JAVA and R. Currently, Python and R are just the wrapper of the internal codes written in Scala. Thus, native Spark users still prefer to using the Scala interface.
Especially after the Spark 2.0 release, Spark SQL becomes part of the new Spark core. Compared with RDD APIs, Spark SQL APIs are user friendly and high level. Internally, Spark SQL contains the Catalyst optimizer, the Tungsten execution engine, and data source integration support. It now powers the next generation streaming engine (i.e., structured streaming), and advanced analytics components (machine learning library MLlib, graph-parallel computation library GraphFrame, and TensorFlow binding library TensorFrames). Therefore, our improvements to Spark SQL can benefit all these user-facing components. That’s why Spark SQL is the most active component in Spark.
Good start!